摘要
音视频相关开发时,如果碰到音频文件或视频文件较大时,通常需要对文件进行压缩,那么音视频文件为什么可以压缩、以什么方法方式压缩等,这些都是音视频压缩需要解决的问题,这篇文章通过从各方面搜集资料来,来大致了解音视频文件压缩的原理,从而加深自己对音视频开发的理解。
所谓压缩,应该就是将文件中冗余的信息(如无关紧要的、或者人无法识别的)去掉,或者以一种更节省空间的方式来重新编码文件。也就是需要从两个方面来入手:
根据使用场景,确定哪些是冗余信息,并通过技术手段见冗余信息去掉;
找到一种更合适的算法,来缩小音视频内容占用的空间。
音频压缩的原理
在了解音频压缩原理之前,先介绍一下音频相关的几个概念:采样和采样频率、采样位数、声道、码率、音频采集和播放。
采样和采样频率
音频采样 指的是 将现有录音的一部分作为音色或片段,直接或经过处理、重建再运用在新作品中的过程。
一秒钟内采样的次数称为采样频率。采样频率越高,越接近原始信号,但是也加大了运算处理的复杂度。根据Nyquist采样定理,要想重建原始信号,采样频率必须大于信号中最高频率的两倍。人能感受到的频率范围为20HZ——20kHZ, 一般音乐的采样频率为44.1kHZ, 更高的可以是48kHZ和96kHZ,不过一般人用耳听感觉不出差别了。语音主要是以沟通为主,不需要像音乐那样清晰,用16k采样的语音就称为高清语音了。现在主流的语音采样频率为16kHz。
采样位数
数字信号是用0和1来表示的。采样位数就是采样值用多少位0和1来表示,也叫采样精度,用的位数越多就越接近真实声音。如用8位表示,采样值取值范围就是-128——127,如用16位表示,采样值取值范围就是-32768——32767。现在一般都用16位采样位数。
声道
声道(Sound Channel) 是指声音在录制或播放时在不同空间位置采集或回放的相互独立的音频信号,所以声道数也就是声音录制时的音源数量或回放时相应的扬声器数量。
码率
码率就是比特率,即每秒传送的比特(bit)数。码率=采样率 x 采样位数 x 声道数。
音频采集和播放
一般用专门的芯片(通常叫codec芯片)采集音频,做AD转换(Analog-to-Digital Converter),然后把数字信号通过I2S总线(主流用I2S总线,也可以用其他总线,比如PCM总线)送给CPU处理(也有的会把codec芯片与CPU芯片集成在一块芯片中)。当要播放时CPU会把音频数字信号通过I2S总线送给codec芯片,然后做DA转换得到模拟信号再播放出来。
音频信号的冗余信息
假如现在有一个 双声道、采样率为44.1KHz、采样位数为16的音频流,那么它的码率就是:
1 | 2 * 44.1 * 1000 * 16 = 1411200 bit/s (约等于 1.411M/s) |
也就是说,这样的音频 每秒要传递 1.411M的数据,这将占用超级大的带宽,所以需要进行音频压缩。
数字音频压缩 指的就是 在保证音频信号在听觉方面不失真的情形下,对音频信号做最大程度的压缩。那么怎么实现呢?数字音频压缩 采用的是 去除声音信号中冗余成分的方法来实现。这里的冗余成分指的是 音频中不能被人耳感知到的信号,它们对确定声音的音色,音调等信息没有任何的帮助。
冗余信号包含人耳听觉范围外的音频信号以及被掩蔽掉的音频信号等。例如,人耳所能察觉的声音信号的频率范围为20Hz~20KHz,除此之外的其它频率人耳无法察觉,都可视为冗余信号。此外,根据人耳听觉的生理和心理声学现象,当一个强音信号与一个弱音信号同时存在时,弱音信号将被强音信号所掩蔽而听不见,这样弱音信号就可以视为冗余信号而不用传送。这就是人耳听觉的掩蔽效应,主要表现在频谱掩蔽效应和时域掩蔽效应,现分别介绍如下:
频谱掩蔽效应
一个频率的声音能量小于某个阈值之后,人耳就会听不到,这个阈值称为最小可闻阈。当有另外能量较大的声音出现的时候,该声音频率附近的阈值会提高很多,即所谓的掩蔽效应。
时域掩蔽效应
当强音信号和弱音信号同时出现时,还存在时域掩蔽效应。即两者发生时间很接近的时候,也会发生掩蔽效应。时域掩蔽过程曲线如图所示,分为前掩蔽、同时掩蔽和后掩蔽三部分。
前掩蔽是指人耳在听到强信号之前的短暂时间内,已经存在的弱信号会被掩蔽而听不到;
同时掩蔽是指当强信号与弱信号同时存在时,弱信号会被强信号所掩蔽而听不到;
后掩蔽是指当强信号消失后,需经过较长的一段时间才能重新听见弱信号,称为后掩蔽;
音频压缩编码的方法
当前数字音频编码领域存在着不同的编码方案和实现方式, 但基本的编码思路大同小异, 如图所示。
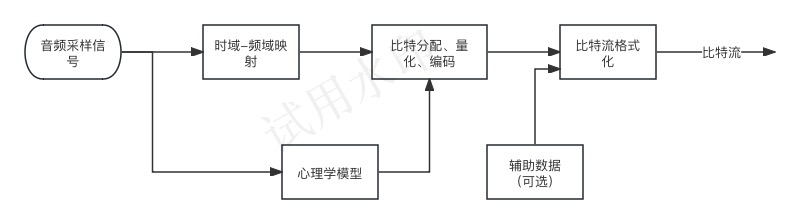
对每一个音频声道中的音频采样信号,首先都要将它们映射到频域中,这种时域到频域的映射可通过子带滤波器实现。每个声道中的音频采样块首先要根据心理声学模型来计算掩蔽门限值, 然后由计算出的掩蔽门限值决定从公共比特池中分配给该声道的不同频率域中多少比特数,接着进行量化以及编码工作,最后将控制参数及辅助数据加入数据之中,产生编码后的数据流。
视频压缩的原理
视频信号的冗余信息
以记录数字视频的YUV分量格式为例,YUV分别代表亮度与两个色差信号。例如对于现有的PAL制电视系统,其亮度信号采样频率为13.5MHz;色度信号的频带通常为亮度信号的一半或更少,为6.75MHz或3.375MHz。以4:2:2的采样频率为例,Y信号采用13.5MHz,色度信号U和V采用6.75MHz采样,采样信号以8bit量化,则可以计算出数字视频的码率为:
1 | 13.5*8 + 6.75*8 + 6.75*8= 216Mbit/s |
如此大的数据量如果直接进行存储或传输将会遇到很大困难,因此必须采用压缩技术以减少码率。数字化后的视频信号能进行压缩主要依据两个基本条件:
数据冗余。例如如空间冗余、时间冗余、结构冗余、信息熵冗余等,即图像的各像素之间存在着很强的相关性。消除这些冗余并不会导致信息损失,属于无损压缩。
视觉冗余。人眼的一些特性比如亮度辨别阈值,视觉阈值,对亮度和色度的敏感度不同,使得在编码的时候引入适量的误差,也不会被察觉出来。可以利用人眼的视觉特性,以一定的客观失真换取数据压缩。这种压缩属于有损压缩。
数字视频信号的压缩正是基于上述两种条件,使得视频数据量得以极大的压缩,有利于传输和存储。一般的数字视频压缩编码方法都是混合编码,即将变换编码,运动估计和运动补偿,以及熵编码三种方式相结合来进行压缩编码。通常使用变换编码来消去除图像的帧内冗余,用运动估计和运动补偿来去除图像的帧间冗余,用熵编码来进一步提高压缩的效率。下文简单介绍这三种压缩编码方法。
压缩编码的方法
变化编码
变换编码的作用是将空间域描述的图像信号变换到频率域,然后对变换后的系数进行编码处理。一般来说,图像在空间上具有较强的相关性,变换到频率域可以实现去相关和能量集中。常用的正交变换有离散傅里叶变换,离散余弦变换等等。数字视频压缩过程中应用广泛的是离散余弦变换。
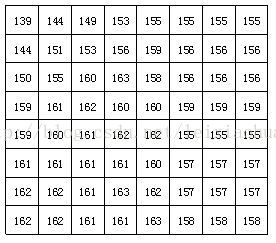
离散余弦变换简称为DCT变换,离散余弦变换的一般步骤:分块、块DCT变换、对DCT变化后的块信息进行量化、对量化结果的非0部分进行压缩编码。
分块,即将视频的帧图像划分成若干个大小相等的块(块中数字表示图像像素的亮度)。
块DCT变化

通过上图可以看出,经过DCT变换后,左上角的低频系数集中了大量能量,而右下角的高频系数上的能量很小。
量化,信号经过DCT变换后需要进行量化。由于人的眼睛对图像的低频特性比如物体的总体亮度之类的信息很敏感,而对图像中的高频细节信息不敏感,因此在传送过程中可以少传或不传送高频信息,只传送低频部分。量化过程通过对低频区的系数进行细量化,高频区的系数进行粗量化,去除了人眼不敏感的高频信息,从而降低信息传送量。因此,量化是一个有损压缩的过程,而且是视频压缩编码中质量损伤的主要原因。
量化过长时有一个公式的,经过量化后,途中的块区域大多数的值都变成了0,既可以舍弃的部分,接下来只需要对非0部分进行压缩就可以了。
- 量化后的非零部分压缩
熵编码
熵编码是因编码后的平均码长接近信源熵值而得名。熵编码多用可变字长编码(VLC,Variable Length Coding)实现。其基本原理是对信源中出现概率大的符号赋予短码,对于出现概率小的符号赋予长码,从而在统计上获得较短的平均码长。可变字长编码通常有霍夫曼编码、算术编码、游程编码等。其中游程编码是一种十分简单的压缩方法,它的压缩效率不高,但编码、解码速度快,仍被得到广泛的应用,特别在变换编码之后使用游程编码,有很好的效果。
首先要在量化器输出直流系数后对紧跟其后的交流系数进行Z型扫描(如图箭头线所示)。Z型扫描将二维的量化系数转换为一维的序列,并在此基础上进行游程编码。最后再对游程编码后的数据进行另一种变长编码,例如霍夫曼编码。通过这种变长编码,进一步提高编码的效率。
运动估计和运动补偿
运动估计(Motion Estimation)和运动补偿(Motion Compensation)是消除图像序列时间方向相关性的有效手段。
上文介绍的DCT变换、量化、熵编码的方法是在一帧图像的基础上进行,通过这些方法可以消除图像内部各像素间在空间上的相关性。实际上图像信号除了空间上的相关性之外,还有时间上的相关性。例如对于像新闻联播这种背景静止,画面主体运动较小的数字视频,每一幅画面之间的区别很小,画面之间的相关性很大。对于这种情况我们没有必要对每一帧图像单独进行编码,而是可以只对相邻视频帧中变化的部分进行编码,从而进一步减小数据量,这方面的工作是由运动估计和运动补偿来实现的。
运动估计技术一般将当前的输入图像分割成若干彼此不相重叠的小图像子块,例如一帧图像的大小为1280720,首先将其以网格状的形式分成4045个尺寸为16*16的彼此没有重叠的图像块,然后在前一图像或者后一个图像某个搜索窗口的范围内为每一个图像块寻找一个与之最为相似的图像块。这个搜寻的过程叫做运动估计。通过计算最相似的图像块与该图像块之间的位置信息,可以得到一个运动矢量。这样在编码过程中就可以将当前图像中的块与参考图像运动矢量所指向的最相似的图像块相减,得到一个残差图像块,由于残差图像块中的每个像素值很小,所以在压缩编码中可以获得更高的压缩比。这个相减过程叫运动补偿。
混合编码
混合编码的一般流程如下:
当前输入的图像首先要经过分块,分块得到的图像块要与经过运动补偿的预测图像相减得到差值图像X,然后对该差值图像块进行DCT变换和量化,量化输出的数据有两个不同的去处:一个是送给熵编码器进行编码,编码后的码流输出到一个缓存器中保存,等待传送出去。另一个应用是进行反量化和反变化后的到信号X’,该信号将与运动补偿输出的图像块相加得到新的预测图像信号,并将新的预测图像块送至帧存储器。
总结
本文主要介绍了音频视频压缩的基本原理,涉及到了音视频压缩的一些基本概念,这为之后学习音视频开发做一个预热,不至于后面谈到音视频压缩以及音视频压缩相关概念而摸不着北。